It was a record wet March in parts of North Carolina, while the entire state experienced warm temperatures and the corresponding arrival of pollen season…
Warm temperatures dominated January, as did wet weather in western North Carolina, which brought our ongoing drought to an end. Mild Weather for a Winter…
Characterized by evolving large-scale patterns and a variety of conditions across North Carolina, from wet to dry and smoky to stormy, 2023 was an interesting…
Fall-like temperatures carried over into December, but our fall drought faded as wetter weather emerged last month. A few areas also picked up snow, but…
Dry weather continued and drought expanded in November, while temperatures ranged from wintry to warm throughout the month. We also close the book on a…
 It was a record wet March in parts of North Carolina, while the entire state experienced warm temperatures and the corresponding arrival of pollen season…
It was a record wet March in parts of North Carolina, while the entire state experienced warm temperatures and the corresponding arrival of pollen season… Things that take a lifetime to build can be destroyed in mere moments. Case in point: March 28, 1984, when a line of tornadoes carved…
Things that take a lifetime to build can be destroyed in mere moments. Case in point: March 28, 1984, when a line of tornadoes carved…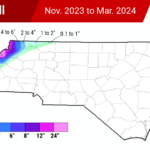 The long-awaited arrival of El Niño late last year helped our winter start with a splash, with multiple rain events across the state in December…
The long-awaited arrival of El Niño late last year helped our winter start with a splash, with multiple rain events across the state in December… Warm weather dominated last month, and so did dry conditions across much of the state. In light of those unseasonable stretches, we look at how…
Warm weather dominated last month, and so did dry conditions across much of the state. In light of those unseasonable stretches, we look at how… Warm temperatures dominated January, as did wet weather in western North Carolina, which brought our ongoing drought to an end. Mild Weather for a Winter…
Warm temperatures dominated January, as did wet weather in western North Carolina, which brought our ongoing drought to an end. Mild Weather for a Winter…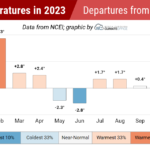 Characterized by evolving large-scale patterns and a variety of conditions across North Carolina, from wet to dry and smoky to stormy, 2023 was an interesting…
Characterized by evolving large-scale patterns and a variety of conditions across North Carolina, from wet to dry and smoky to stormy, 2023 was an interesting… Fall-like temperatures carried over into December, but our fall drought faded as wetter weather emerged last month. A few areas also picked up snow, but…
Fall-like temperatures carried over into December, but our fall drought faded as wetter weather emerged last month. A few areas also picked up snow, but… Dry weather continued and drought expanded in November, while temperatures ranged from wintry to warm throughout the month. We also close the book on a…
Dry weather continued and drought expanded in November, while temperatures ranged from wintry to warm throughout the month. We also close the book on a…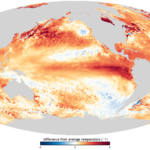 Following a snow-free year in many areas and with drought now gripping more than half of the state, a pattern change – both from what…
Following a snow-free year in many areas and with drought now gripping more than half of the state, a pattern change – both from what…